人工智能大模型的迅猛发展与广泛应用,使得算力成为重大的战略抓手与基础设施。长期以来电子芯片的算力增长支撑着AI模型规模的不断发展,然而其高能耗亦带来了前所未有的能源挑战,新兴计算范式的建立与发展迫在眉睫。以光为计算媒介,以光的可控传播构建计算模型,光计算以其高算力低能耗特性打开了智能计算的新赛道,在后摩尔时代展现出巨大的潜力。
训练和推理是AI大模型核心能力的两大基石,缺一不可。通用智能光计算芯片“太极”[Science 2024]的问世, 首次将光计算从原理验证推向了大规模实验应用,以160TOPS/W的系统级能效为复杂智能任务的“推理”带来了曙光,但却未能释放光计算的“训练之能”。相较于推理而言,模型训练对算力更为亟需,然而电训练架构要求前向-反向传播模型高度匹配,这对光计算物理系统的精准对齐提出了苛刻的要求,致使梯度计算难、离线建模慢、映射误差大,极大地禁锢了光训练的规模与效率。
清华大学电子工程系、信息国家研究中心方璐教授课题组,自动化系、信息国家研究中心戴琼海教授课题组,另辟蹊径,构建了光子传播对称性模型,摒弃了电训练反向传播范式,首创了全前向智能光计算训练架构,研制了通用光训练芯片“太极-II”,摆脱了对离线训练的依赖,支撑智能系统的高效精准光训练,相关研究成果近期发表于《Nature》。太极-II的面世,填补了智能光计算在大规模训练这一核心拼图的空白,将与太极-I合力,为AI大模型训练与推理注入算力发展的新动力,构建光算力新基座。

论文发表截图
物理是自然界的语言,也是一切问题的答案。经典物理学对称之美的微光,通过现代物理学的刻画延伸,建立了时光之美,信息解释了时光之变,击中了21世纪的人工智能光计算领域。全前向光训练突破了电训练架构对物理光计算的掣肘,将梯度下降中的反向传播化为光学系统的前向传播,两次前向传播具备天然的对齐特性,保障了物理梯度的计算精度。与此同时,物理光系统的调制-传播与神经网络的激活-连接相互映射,即调制模块的训练可驱动任意网络的权重优化,从而保障了训练的速度与能效。系统实测结果表明,太极-II突破了精度与效率的矛盾,将数百万参数的光网络训练速度提升了1个数量级,代表性智能任务的准确率提升40%。在非视域等复杂场景成像应用中,实现了千赫兹帧率的智能成像,效率提升2个数量级。除此之外,太极-II在拓扑光子学领域亦展露出应用潜力,在不依赖任何模型先验下可自动搜索非厄米奇异点,为高效精准解析复杂拓扑系统提供了新思路。
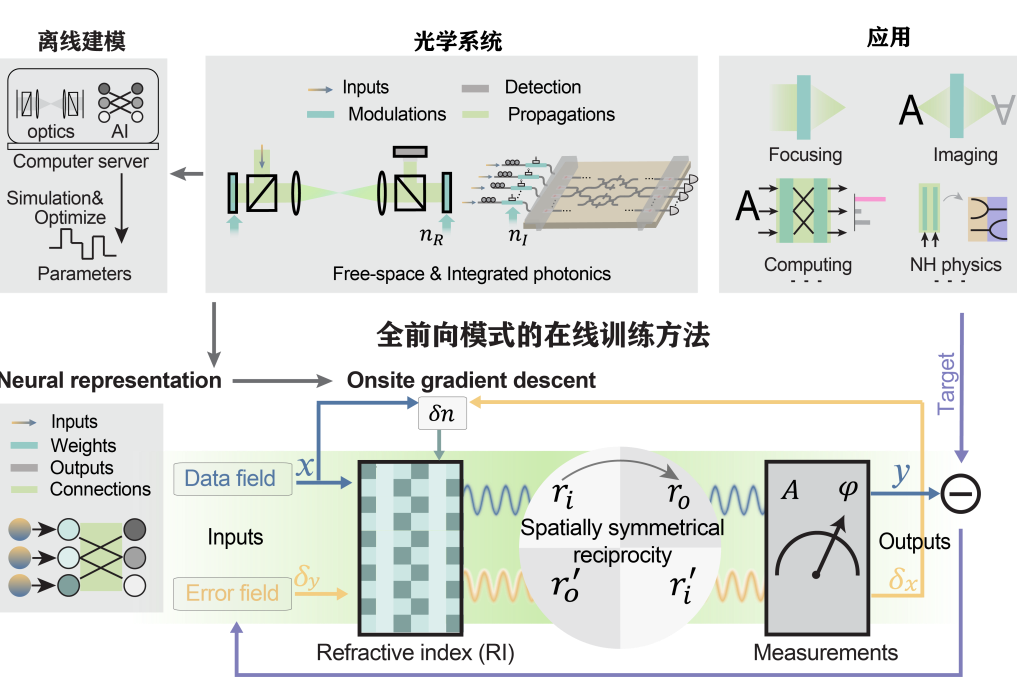
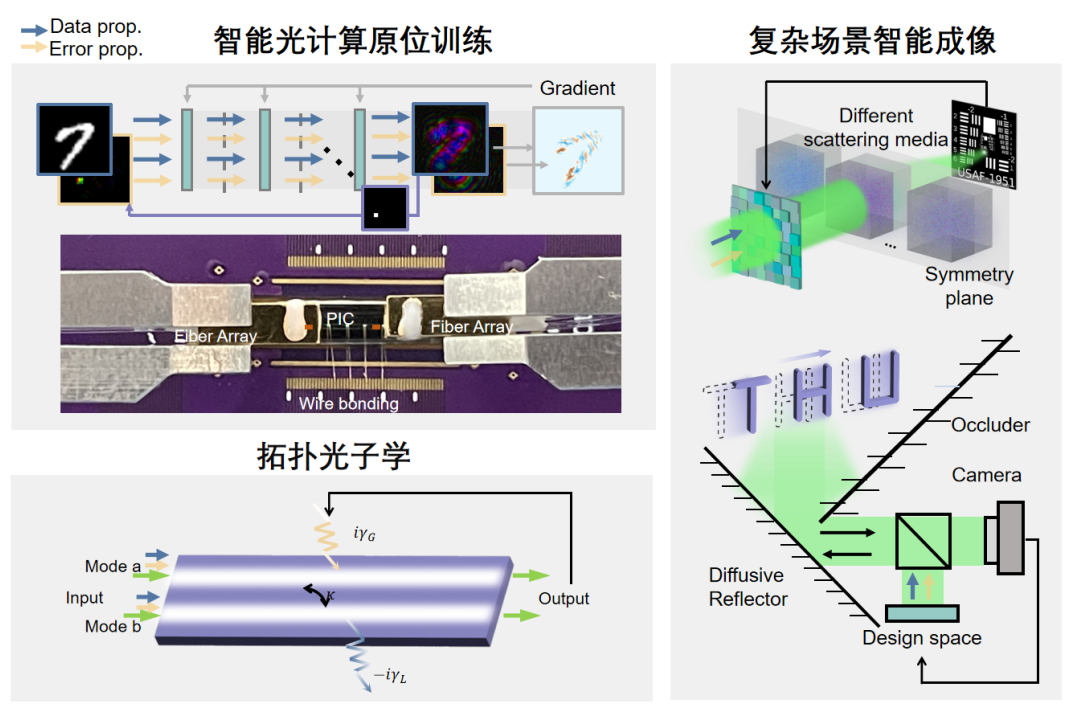
正反互易:全前向传播光训练架构(左图);光学共通:通用光训练赋能复杂系统(右图)
如两仪分立,太极-I和II分别实现了高能效AI推理与训练;又如两仪调和,太极-I和II共同构成了大规模智能计算的完整生命周期,开启了智能光计算的新时代。在原理样片的基础上,研究团队正积极地向智能光芯片产业化迈进,在多种端侧智能系统上进行了应用部署。可以预见,智能光计算平台将逐步登上AI算力舞台,破除人工智能算力困局,以更低的资源消耗和更小的边际成本,为人工智能大模型、通用人工智能、复杂智能系统的高速高能效计算开辟新路径。
该研究工作以“光神经网络全前向训练”(Fully forward mode training for optical neural networks)为题,发表于Nature《自然》期刊。清华大学电子系为论文第一单位,方璐教授、戴琼海教授为论文的通讯作者,清华大学电子系博士生薛智威、博士后周天贶为共同一作,电子系博士生徐智昊、之江实验室虞绍良博士参与了本项工作。本课题受到国家科技部、国家自然科学基金委、北京信息科学与技术国家研究中心、清华大学-之江实验室联合研究中心的支持。
论文链接:https://www.nature.com/articles/s41586-024-07687-4
(来源:电子系)



